Aud2Repr2Pose: Analyzing input and output representations for speech-driven gesture generation
Taras Kucherenko, Dai Hasegawa, Gustav Eje Henter, Naoshi Kaneko, Hedvig Kjellström
[AAMAS'19] | [IVA'19] | [IJHCI'21]
ABSTRACT
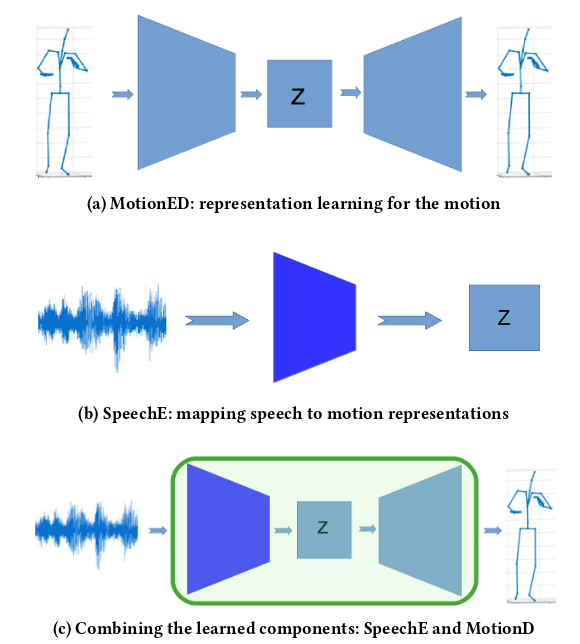
This paper presents a novel framework for speech-driven gesture production, applicable to virtual agents to enhance human-computer interaction. Specifically, we extend recent deep-learning-based, data-driven methods for speech-driven gesture generation by incorporating representation learning. Our model takes speech as input and produces gestures as output, in the form of a sequence of 3D coordinates.
We provide an analysis of different representations for the input (speech) and the output (motion) of the network by both objective and subjective evaluations. We also analyse the importance of smoothing of the produced motion.
Our results indicated that the proposed method improved on our baseline in terms of objective measures. For example, it better captured the motion dynamics and better matched the motion-speed distribution. Moreover, we performed user studies on two different datasets. The studies confirmed that our proposed method is perceived as more natural than the baseline, although the difference in the studies was eliminated by appropriate post-processing: hip-centering and smoothing. We conclude that it is important to take both motion representation and post-processing into account when designing an automatic gesture-production method.
Main video explaining the paper:
Below is a demo applying that model to a new dataset (which is in English). To reproduce the results you can use our pre-trained model
Citation format:
@article{kucherenko2021moving,
author = {Taras Kucherenko and Dai Hasegawa and Naoshi Kaneko and Gustav Eje Henter and Hedvig Kjellström},
title = {Moving Fast and Slow: Analysis of Representations and Post-Processing in Speech-Driven Automatic Gesture Generation},
journal = {International Journal of Human–Computer Interaction},
volume = {37},
number = {14},
pages = {1300-1316},
year = {2021},
publisher = {Taylor & Francis},
doi = {10.1080/10447318.2021.1883883},
URL = {https://doi.org/10.1080/10447318.2021.1883883},
eprint = {https://doi.org/10.1080/10447318.2021.1883883}
}