Gesticulator: A framework for semantically-aware speech-driven gesture generation
Taras Kucherenko, Patrik Jonell, Sanne van Waveren, Gustav Eje Henter, Simon Alexanderson, Iolanda Leite, Hedvig Kjellström
International Conference on Multimodal Interaction (ICMI '20)
BEST PAPER AWARD
[Paper] [Code] [Experimental Data]
ABSTRACT
During speech, people spontaneously gesticulate, which plays a key role in conveying information. Similarly, realistic co-speech gestures are crucial to enable natural and smooth interactions with social agents. Current data-driven co-speech gesture generation systems use a single modality for representing speech: either audio or text. These systems are therefore confined to producing either acoustically-linked beat gestures or semantically-linked gesticulation (e.g., raising a hand when saying “high”): they cannot appropriately learn to generate both gesture types. We present a model designed to produce arbitrary beat and semantic gestures together. Our deep-learning based model takes both acoustic and semantic representations of speech as input, and generates gestures as a sequence of joint angle rotations as output. The resulting gestures can be applied to both virtual agents and humanoid robots. Subjective and objective evaluations confirm the success of our approach.
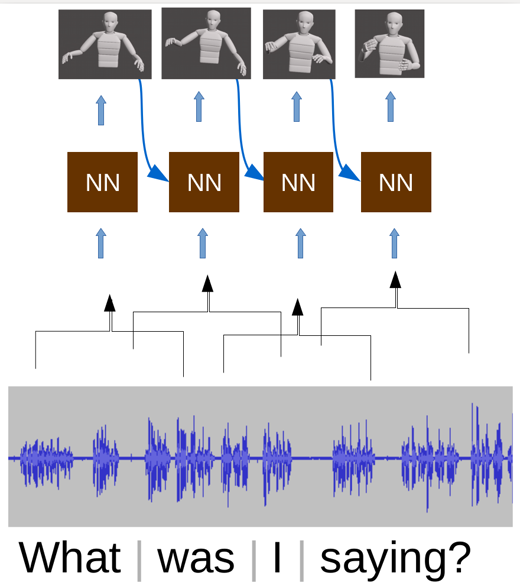
Additional resources:
- Video samples from the ablation study DOI: 10.6084/m9.figshare.13055609
- 3D coordinates from the ablation study DOI: 10.6084/m9.figshare.13055597
- BVH files from the ablation study DOI: 10.6084/m9.figshare.13603169
-
Ablation user study results DOI: 10.6084/m9.figshare.13055585
- Video samples from the baselining study DOI: 10.6084/m9.figshare.13061294
- 3D coordinates from the baselining study DOI: 10.6084/m9.figshare.13061270
- BVH files from the baselining study DOI: 10.6084/m9.figshare.13603202
- Baselining user study results DOI: 10.6084/m9.figshare.13061249
Erratum:
-
- We discovered an issue with the velocity loss implementation used for our experiments. The bug was fixed in this commit. The experimental results involving velocity loss were hence not correct and should be disregarded. We are going to conduct a new experiment with the proper velocity loss implementation and will share the results on this project webpage.
-
- We have identified a minor error in our paper concerning the results of PCA. The PCA we used had 12 components (as stated), but these accounted for 92% of the variation on the training set, and not 95% like the paper published at ICMI suggests. The error was corrected in online postprints of the article.
Press

![]()


Citation format:
@inproceedings{kucherenko2020gesticulator,
title={Gesticulator: A framework for semantically-aware speech-driven gesture generation},
author={Kucherenko, Taras and Jonell, Patrik and van Waveren, Sanne and Henter, Gustav Eje and Alexanderson, Simon and Leite, Iolanda and Kjellstr{\"o}m, Hedvig},
booktitle={Proceedings of the ACM International Conference on Multimodal Interaction},
year={2020}
}